


Are you tired of spending countless hours manually extracting terminology from lengthy texts? Do you wish there was a faster and more accurate way to identify the most relevant terms? Look no further! In this article, I am excited to share my journey in developing TermXT, an innovative tool for terminology extraction that harnesses the capabilities of Natural Language Processing (NLP) and it is designed with terminology management workflows in mind.
Extracting Terminology Made Efficient
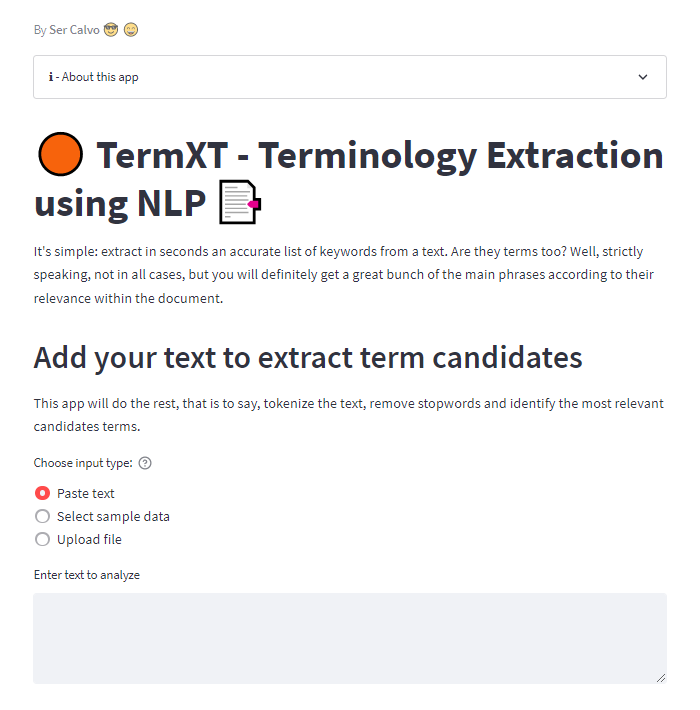
The process of extracting relevant terminology from texts can be tedious and time-consuming. Recognizing this challenge, I set out to create TermXT to simplify and streamline the process. By leveraging state-of-the-art NLP techniques, I developed a tool that automates the extraction of significant terms and keywords from various types of texts.
TermXT offers a user-friendly interface powered by Streamlit that allows you to upload your text and obtain a comprehensive analysis with just a few clicks. The tool tokenizes the text, eliminates common stopwords, and generates a list of candidate terms. These terms are then ranked based on their relevance, ensuring that you can focus on the most important concepts within your text. With TermXT, the once laborious task of manual term extraction becomes a breeze.
Leveraging Cutting-Edge NLP Libraries
Behind the scenes, TermXT harnesses the power of cutting-edge NLP libraries to achieve its performance. One of the key components is KeyBERT, a library that utilizes multiple NLP embeddings and the powerful Transformers library from Hugging Face. By employing this approach, TermXT extracts the most relevant keywords and keyphrases, capturing the essence of your text accurately.
In addition, TermXT incorporates keyphrase-vectorizers, which automatically determine the optimal number of n-grams to include in the extracted terms. This adaptive approach ensures that both single-word terms and multi-word keyphrases are identified, providing a comprehensive view of the text’s terminology.
Enhancing Terminology Harvesting with Metadata
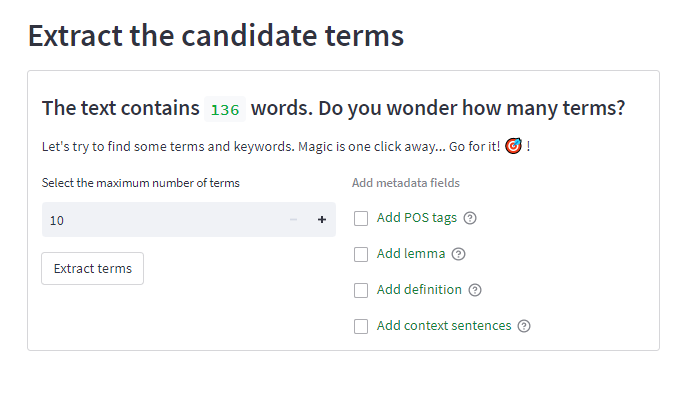
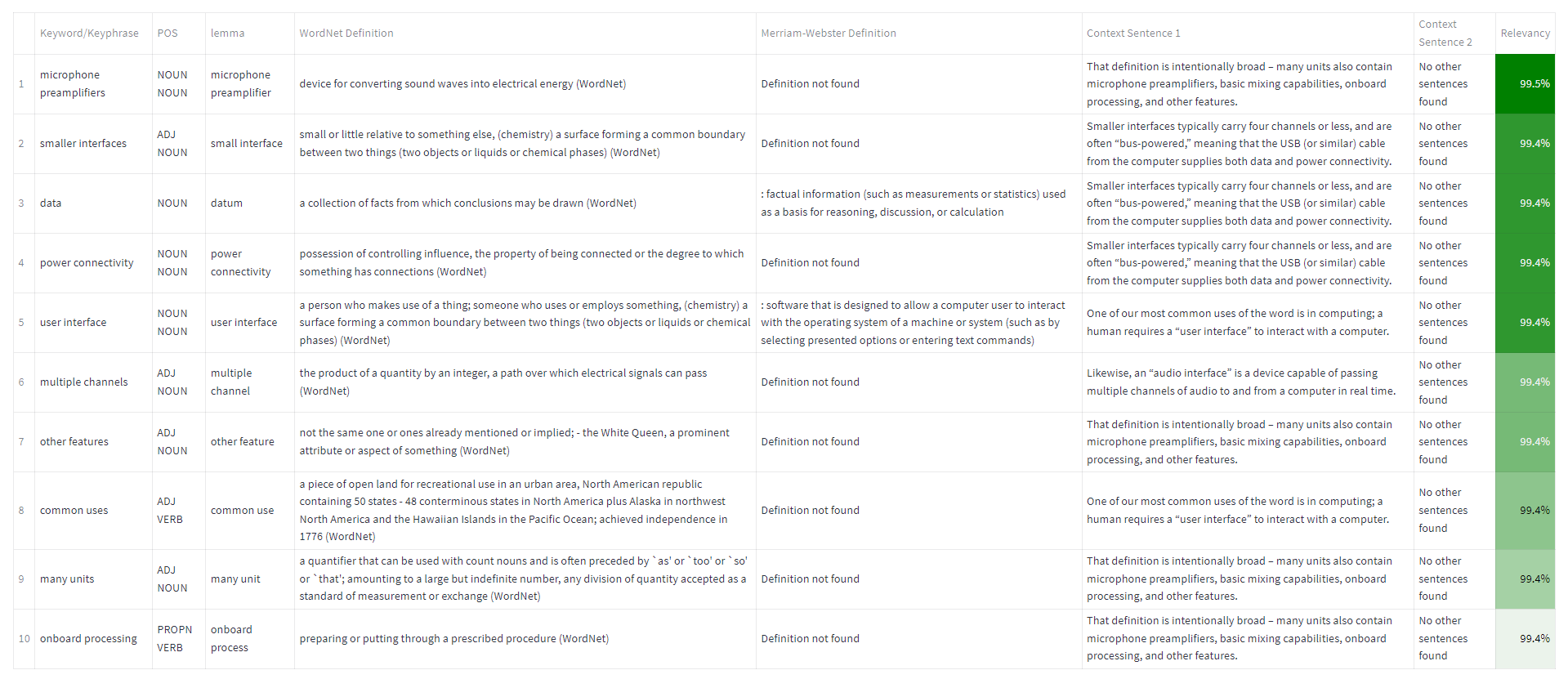
Extracting terminology is quite relevant already, but it’s not all in terminology harvesting. So this is why I thought that TermXT should go beyond simple terminology extraction and be able to provide valuable metadata for each term. To enrich the extracted terms, I enabled options such as Part-of-Speech (POS) tagging, lemma extraction, definition retrieval from authoritative sources like WordNet and Merriam-Webster, and the inclusion of context sentences. A Swiss-knife solution!
-
-
- POS Tags and Lemmas: With the click of a button, TermXT can add Part-Of-Speech (POS) tags and lemmas to each extracted term.
- Definitions at Your Fingertips: It seamlessly integrates WordNet and Merriam-Webster definitions
- Contextual Sentences: It automatically generates random sentences from the input text that contain the extracted terms.
-
By leveraging POS tagging, I could gain insights into the grammatical categories of the terms. The lemma extraction reveals the canonical forms of the terms, aiding in their understanding and harmonization of term entries. Furthermore, by including definitions and random context sentences, TermXT provides a glimpse of how the terms are used in real-world contexts. This additional metadata is great to delve deeper into the terminology and facilitates a more comprehensive understanding.
Last word
I embarked on a journey to develop a terminology extraction tool by leveraging the capabilities of NLP and incorporating cutting-edge libraries like KeyBERT and keyphrase-vectorizers. I achieved a solution that simplifies and automates the extraction of relevant terms and keywords.
TermXT helps me to uncover the essential concepts within their texts, saving valuable time and effort. The inclusion of metadata values such as POS tags, lemmas, definitions, and context sentences enhances the understanding and usage of the extracted terms, enabling knowledge sharing, research, and content creation.
I invite you to explore TermXT and experience the power of terminology extraction firsthand. You can find it in https://locnlp23lab.streamlit.app. Enjoy it! And please send me a comment if you have any idea or feedback to share!




